*** 교수님의 주의사항 ***
만약 coursera 수강생이라면,
프로그래밍 과제는 최대한 스스로의 힘으로 해보고, 도저히 막히는 부분이나 이해가 가지 않은 부분만을
남의 도움을 받기를 추천한다고 합니다.
저번 글에 이어서, 바로 4-7부터 진행하겠습니다.

nn_model() 함수 구현으로 이전의 함수들을 모두 통합하겠습니다.
--> nn_model() 함수를 프로그래밍 해봅시다.

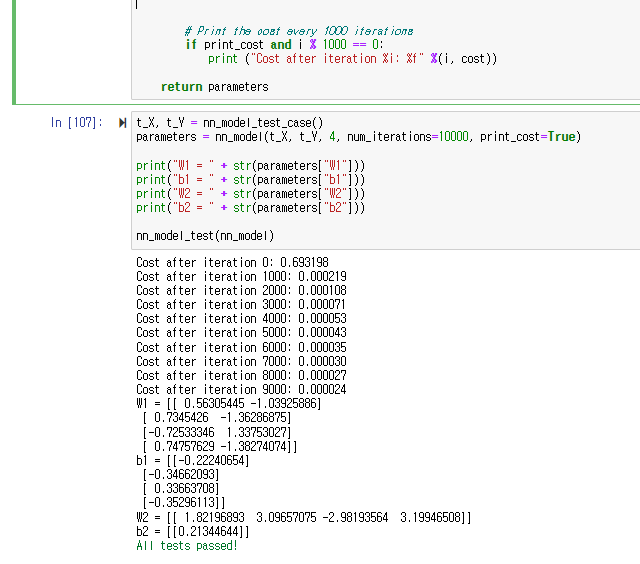
아래의 구현해 준 함수들을 모두 불러와줍시다.
0단계 : initialize_parameters() --> (layer의 크기에 맞게) 매개변수 w, b를 초기화
1단계 : forward_Propagation() --> 순정파 계산을 통해서, 예측치 계산
2단계 : compute_cost() ---> 예측치와 정답 데이터 간의 오차를 뜻하는 비용을 계산
*참고 : 이 강의에서는 단일 예시에 대한 오차는 손실, 전체 예시에 대한 오차는 비용이라고 부릅니다.
3단계 : backward-propagation() --> 역전파 계산을 통해서, 경사 하강법에 필요한 도함수 값을 계산
*참고 : 경사하강법에서 도함수는 손실을 최소화하는 업데이트 방향이 어딘지 알려줌
4단계 : update_parameters() ---> 구한 도함수 값으로 매개변수 w, b를 업데이트
1~4단계를 한 묶음으로 생각하여, 4개의 단계를 거치면 1번 학습한다는 의미입니다.
이를 for 구문을 이용하여 10000번 반복하여,
오차(비용)를 최소화하는 방향으로 매개변수 w, b를 1000번 수정하면 모델 만들기 끝입니다

위의 학습 결과를 보면, 학습을 반복하면 할수록 모델의 오차가 줄어드는 것을 확인할 수 있습니다!
참고 --> 이 값은 저희가 분류하고자 하는 평면 데이터에 대한 오차가 아니라,
내용을 쉽게 이해하기 위해서 제공된 임의의 테스트 데이터입니다.

10000번 수정된 최종 매개변수의 값도 확인할 수 있습니다.
이제 학습을 마친 모델을 테스트해보기 전에, 테스트 함수를 구현해 보겠습니다.
5 - Test the Model + 연습문제 9번 (예측 모델 만들기)

모델을 테스트하기 위해 쓰이는 predict() 함수를 만들어봅시다.
테스트하고자 하는 이미지 데이터를 X_test라 하면,
이전의 순정파 과정과 마찬가지로, X_test 데이터를 입력 -> 순정파 과정 -> 예측치 계산
여기서 예측치가 0.5보다 크면 1(True), 0.5보다 작으면 0(False)로 판정합니다.
예를 들어,
임곗값을 기반으로 행렬 X의 항목을 0과 1로 설정하려면 다음과 같이 하십시오. X_new = (X > 임곗값)

A2 , cache는 저번에 구현한 forward_propagation()를 불러와서 저장해주고,
A2는 Y-hat, 즉 예측치를 의미합니다.
이제 힌트를 참고하여 코드를 작성하면 됩니다.
*참고) predictions = A2 > 0.5의 의미
----> A2 > 0.5면 True 값이 입력되고, 아니면 False 값이 Predictions에 입력됩니다.
이제 predict()를 통해서, 학습을 마친 모델을 테스트해 보겠습니다.
5 - 2 만든 딥러닝 모델로 평면 데이터 분류 테스트해보기
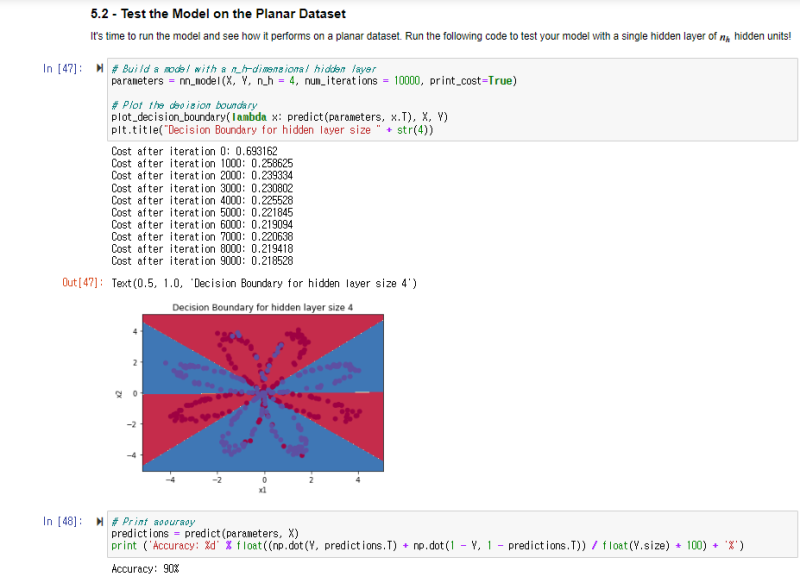
저희가 원래 분류하기로 했던 평면 데이터를 테스트해 보겠습니다.
학습이 거듭될수록, 오차가 낮아지는 걸 확인할 수 있습니다.

10000번 학습 후에,
저희가 만든 딥러닝 모델이 분류한 평면 데이터의 모습을 확인할 수 있습니다.
(아래와 비교해 봅시다.)

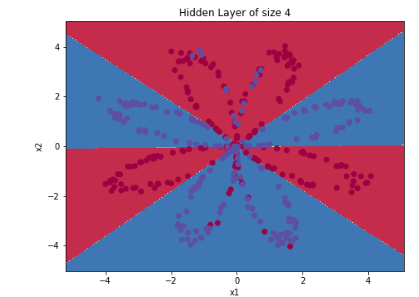
위의 그림은 과제 맨 처음에 나온, 단순 로지스틱 회귀를 이용한 분류입니다.
파란색 점이 빨간색 영역에 많이 남아있고, 빨간색 점이 파란색 영역에 많이 남아있는 모습이지만,
저희가 만든 신경망 학습을 이용한 로지스틱 회귀 모델은 훨씬 정확하게 영역을 나눈 모습을 확인할 수 있습니다.
저희가 만든 모델의 정확도는 90%로써,
단순 로지스틱 회귀 모델의 정확도가 47%였던걸 비교하면 상당히 정확 진 것이죠.

과제를 통해서 배운 점
- 은닉층이 있는 완전한 이진 분류 신경망 구축
- 비선형 함수를 잘 활용
- 교차 엔트로피 손실을 계산
- 정방향 및 역방향 전파 구현 (순정파, 역전파와 같은 뜻)
- 과적함을 포함하여 은닉층 크기 변경에 따른 모델 성능 변화
저희는 과제를 통해서 패턴을 학습할 수 있는 신경망을 만들었습니다.
이상으로 3주 차 과정이 끝났습니다. 수고하셨습니다!
++ 은닉층의 수에 따른 예측 정확도의 변화 (선택 사항)




은닉층의 수가 너무 많으면, 과적 합의 생겨버려서 오히려 모델의 성능이 떨어지게 됩니다.
가장 좋은 은닉층 크기는 약 n_h = 5인 것 같습니다.
나중에는, 과적합 없이 매우 큰 모델(예: n_h = 50)을 사용할 수 있는 정규화에 익숙해질 것입니다.
이 내용들은 모두 coursera에서 앤드루 응 교수님의 강의를 요약정리 및 쉽게 재 풀이하여 적은 글이며,
내용에는 생략되거나 변형된 부분이 많으니 직접 강의를 들어보시는 걸 추천드립니다!
이 글은 상업적 목적이 아닌, 한국에서 인공지능을 배우고 싶은 분들을 위해 적은 교육적 목적에서 작성하였습니다.
'코세라 앤드류 응 AI 강의 리뷰' 카테고리의 다른 글
| [인공지능 강의 리뷰] 23 - 왜 신경망의 층을 깊게하는 걸까? ( why deep repretations?) (0) | 2022.07.05 |
|---|---|
| [인공지능 강의 리뷰] 22 - 딥러닝에서 행렬의 크기 알아보기(Getting your matrix dimensions right) (0) | 2022.06.01 |
| [인공지능 강의 리뷰] 21 - L층의 뉴럴 네크워크(Deep L-layer Neural Networks) (0) | 2022.05.31 |
| [인공지능 강의 리뷰] 19 - 하나의 숨겨진 레이어를 사용한 평면 데이터 분류. 프로그래밍 과제 (0) | 2022.05.18 |
| [인공지능 강의 리뷰] 18 - 하나의 숨겨진 레이어를 사용한 평면 데이터 분류. 프로그래밍 과제 (2) | 2022.05.17 |
| [인공지능 강의 리뷰] 17 - 총정리 퀴즈. 얕은 신경망(Shallow Neural Network) (0) | 2022.05.17 |
| [인공지능 강의 리뷰] 16 - 왜 활성화 함수에 비선형 함수를 써야할까? (0) | 2022.05.17 |