
이번 시간에는 저번 주와 마찬가지로 3주 차 전체 내용을 활용하여,
평면 데이터를 분류하는 딥러닝 학습모델을 프로그래밍 과제를 해보겠습니다

이번 과제로 만들 모델은 "은닉층"이 있는 모델이기에,
이 모델과 이전에 로지스틱 회귀를 사용하여 구현한 (은칙층이 없는) 모델 간에 큰 차이가 있음을 알 수 있습니다.
참고) 저번 고양이 분류기 과제에서는, 은닉층이 없었습니다. (아래의 자료는 저번 주 과제입니다.)

이 과제가 끝나면 다음을 수행할 수 있습니다.
1 - 단일 은닉층으로 2등급 분류 신경망 구현
2 - tanh와 같은 비선형 활성화 함수 사용
3 - 교차 엔트로피 손실 계산
4 - 순방향 및 역방향 계산 과정
전체 목차

목차는 다음과 같이 구성됩니다.
목차를 확인하면서, 바로 1단계부터 차근차근 시작해 봅시다.
1 - Packages ( 프로그래밍을 위한 기본 세팅)

저번처럼 파이썬 코딩을 하기 전에, 딥러닝 모델 구현에 필요한 패키지부터 정의해 줍시다.
각 패키지에 대한 설명 :
numpy는 Python을 사용한 과학 컴퓨팅을 위한 기본 패키지입니다.
-sklearn은 데이터 마이닝 및 데이터 분석을 위한 간단하고 효율적인 도구를 제공합니다.
matplotlib는 Python에서 그래프를 그리기 위한 라이브러리입니다.
testCases는 함수의 정확성을 평가하기 위한 몇 가지 테스트 예제를 제공합니다.
planar_utils는 이 과제에 사용되는 다양한 유용한 기능을 제공합니다.
2 - Load the Dataset ( 훈련 및 테스트 할 데이터 불러오기)

패키지를 정의해 준 후, 과제에서 준비된 데이터 셋을 불러서 변수 X, Y에 저장해 줍시다.
그 후, matplotlib를 사용하여 데이터세트를 시각화(Visualize) 하겠습니다.
데이터는 빨간색(레이블 y=0)과 파란색(y=1) 포인트가 있는 "꽃"처럼 보입니다.
목표는 이 데이터에 맞는 모델을 구축하는 것입니다.
즉, 저희가 만들 딥러닝 분류기가 영역을 빨간색 또는 파란색으로 잘 나누게 하는게 목표입니다.

문제에서 지시한 대로, 저희가 직전 불러왔던 X, Y를 각각 행렬의 크기를 나타내 주는 shape() 함수에 넣어서,
변수 shape_X와 shape_Y를 정의해 줍시다.
m은 트레이닝 셋의 개수를 나타내므로,X.shape [1]로 정의해 줍시다.
--> 참고 : X.shape[0]은 2인데, 이것은 입력해 줄 x의 특징이 2개라는 걸 의미합니다.
즉, shape of X = (2, 400)은 X 데이터의 특징의 수 * X 데이터의 개수라는 뜻입니다.
3 - 단순 로지스틱 회귀
전체 신경망을 구축하기 전에, 이 문제에 대해 단순 로지스틱 회귀는 어떻게 수행되는지 확인하겠습니다.
이를 위해 sklearn의 내장 기능을 사용하겠습니다.
아래 코드를 실행하여 데이터 세트에 대한 단순 로지스틱 회귀 분류기를 사용해 보세요.

이제 이러한 모델의 결정 경계를 그릴 수 있습니다! 아래 코드를 실행하세요.
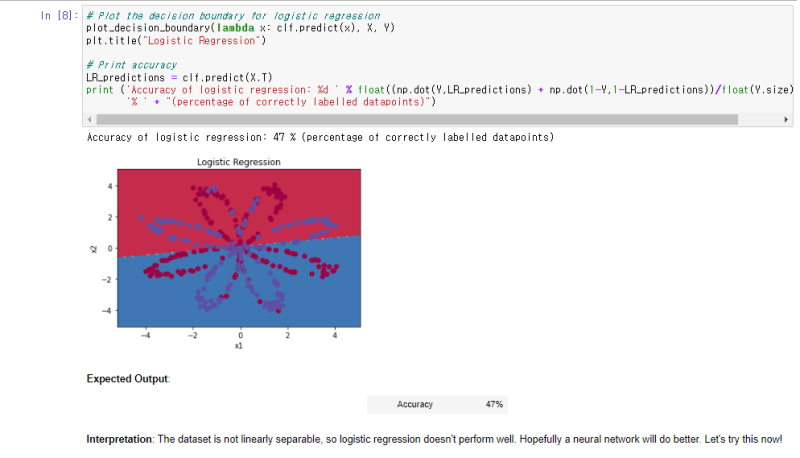
데이터 세트는 단순히 선형으로 분리할 수 없으므로, 단순 로지스틱 회귀만으로는 잘 수행되지 않습니다.
"은닉층"이 없는 단순 신경망 모델의 한계점 : 단순 선형 문제만 해결 가능, 위의 문제는 단순 선형 문제가 아님
저희는 높은 정확성을 원하기 때문에, "은닉층"을 추가하여 신경망 학습을 시킨 후, 로지스틱 회귀를 할 것입니다.
다음으로 넘어가 봅시다.
4 - 신경망 모델(Neural Network model)
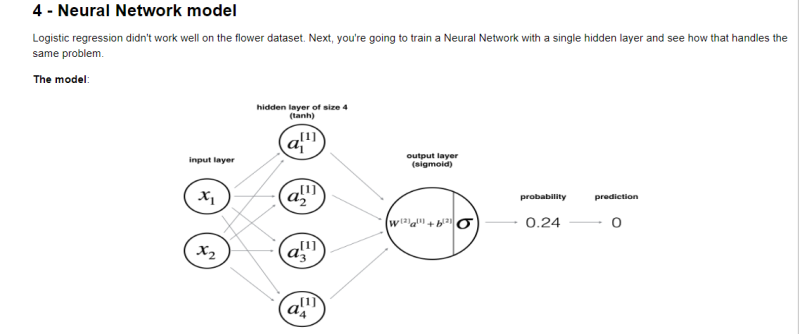
위와 같은 "은닉층"을 추가해 보겠습니다. (저번 과제에서 "은닉층"을 추가했다고 생각하면 됩니다.)
위의 모델을 수학적으로 표현하면 아래와 같습니다,

-- 신경망을 구축하는 일반적인 방법은 다음과 같습니다 ---
1.신경망 구조를 정의합니다(입력 유닛 수, 은닉 유닛 수 등).
2.모델의 매개변수 초기화
3.아래의 4개의 단계 반복:
- - 순방향 전파 구현
- - 손실(=비용) 계산
- - 기울기를 얻기 위해 역전파를 구현합니다.
- - 업데이트 매개변수(경사 하강법)
실제로 1- 3단계를 계산하는 함수를 만든 다음 nn_model()이라는 하나의 함수로 병합하는 경우가 많습니다.
nn_model()을 빌드하고 올바른 매개변수를 학습하면 새 데이터에 대한 예측을 수행하겠습니다.
-----> 1단계부터 진행해봅시다.


n_x , n_h , n_y는 각각 입력, 은닉, 걸과 층의 레이어 크기를 나타내는 변수라고 합니다.
--> ( 여기서 레이어 크기는 각 층에 속하는 퍼셉트론의 수를 의미합니다.)
n_h는 문제에서 4라고 정의해 주었고, n_x 와 n_y는 입력 데이터 X, 결과 Y의 특징 수를 의미합니다.
--> Ex) Exercise 1에서는 ( 1 or 0)로 Y의 특징이 1차원으로 정의되었기에, 특징 수는 1이었습니다.
Exercise 1 참고) shape [0]은 특징 수를 나타내니, 이것들을 코드로 입력해 주면 됩니다.

지침서:
- 매개변수의 크기가 올바른지 확인하십시오. 필요한 경우 위의 신경망 그림을 참조하십시오.
- 임의의 값으로 가중치 w의 행렬 값을 초기화합니다.
- np.random.randn(a, b) * 0.01을 사용하여 a* b 모양의 행렬을 무작위로 초기화합니다.
- b벡터(=행렬)를 0으로 초기화합니다.
- np.zeros((a, b))를 사용하여 (a, b) 모양의 행렬을 0으로 초기화합니다.
---> 지침서를 이용하여, 코딩해봅시다


문제에서 알려준 매개변수에 대한 설명을 봅시다.
W1 = 은닉층의 크기 * 입력층의 크기 * 0.01
----> 0.01은 가중치를 작게 해서 계산량을 낮춰, 학습을 빠르게 하기 위한 숫자
b1 = 입력층의 크기 * 1
---> 퍼셉트론 하나당 편향 b는 1개이므로 1을 곱함
W2 = 결과층의 크기 * 은닉층의 크기 * 0.01
--> 은닉층의 결과가 W2의 입력 값이 될 것이므로.
b2 = 결과층의 크기 * 1
문제에서 w의 값은 np.random.randn() 코드를 사용하여 랜덤으로 초기화하라고 했고,
b의 값은 np.zeros() 코드를 사용하여 0으로 초기화하라고 했으므로.
이를 종합하여 코드로 정의해 주면 됩니다!
글이 너무 길어져서, 여기에서 한번 끊고 다음 글에서 이어서 진행하겠습니다!
4-2까지 오늘 진행하였고, 4-3부터 다음 글에서 진행하겠습니다.
이 내용들은 모두 coursera에서 앤드루 응 교수님의 강의를 요약정리 및 쉽게 재 풀이하여 적은 글이며,
내용에는 생략되거나 변형된 부분이 많으니 직접 강의를 들어보시는 걸 추천드립니다!
이 글은 상업적 목적이 아닌, 한국에서 인공지능을 배우고 싶은 분들을 위해 적은 교육적 목적에서 작성하였습니다.
'코세라 앤드류 응 AI 강의 리뷰' 카테고리의 다른 글
| [인공지능 강의 리뷰] 21 - L층의 뉴럴 네크워크(Deep L-layer Neural Networks) (0) | 2022.05.31 |
|---|---|
| [인공지능 강의 리뷰] 20 - 하나의 숨겨진 레이어를 사용한 평면 데이터 분류. 프로그래밍 과제 (0) | 2022.05.19 |
| [인공지능 강의 리뷰] 19 - 하나의 숨겨진 레이어를 사용한 평면 데이터 분류. 프로그래밍 과제 (0) | 2022.05.18 |
| [인공지능 강의 리뷰] 17 - 총정리 퀴즈. 얕은 신경망(Shallow Neural Network) (0) | 2022.05.17 |
| [인공지능 강의 리뷰] 16 - 왜 활성화 함수에 비선형 함수를 써야할까? (0) | 2022.05.17 |
| [인공지능 강의 리뷰] 15 - 뉴럴 네트워크 And 벡터화 표현 (0) | 2022.05.17 |
| [인공지능 강의 리뷰] 14 - 프로그래밍 과제 . 신경망 사고방식을 이용한 로지스틱 회귀 모델 만들기3 (고양이 사진 분류기) (0) | 2022.05.16 |