코세라 (Coursera) 앤드류 응 교수님의 인공지능 강의 1번째 코스, 신경망 및 딥러닝 코스 2주 차 강의 리뷰입니다.
목차
- 1. 이진 분류(Binary Classification)란?
- 2. 이진 분류 문제를 해결할 때 사용하는 통계기법 : 로지스틱 회귀(Logistic Regression)
1. 이진 분류(Binary classification)란?

저번 1주 차에 이어서, 2주 차 강의 리뷰를 시작하겠습니다.
2주 차 강의의 시작은 "이진 분류(Binary Classification)"으로 시작합니다
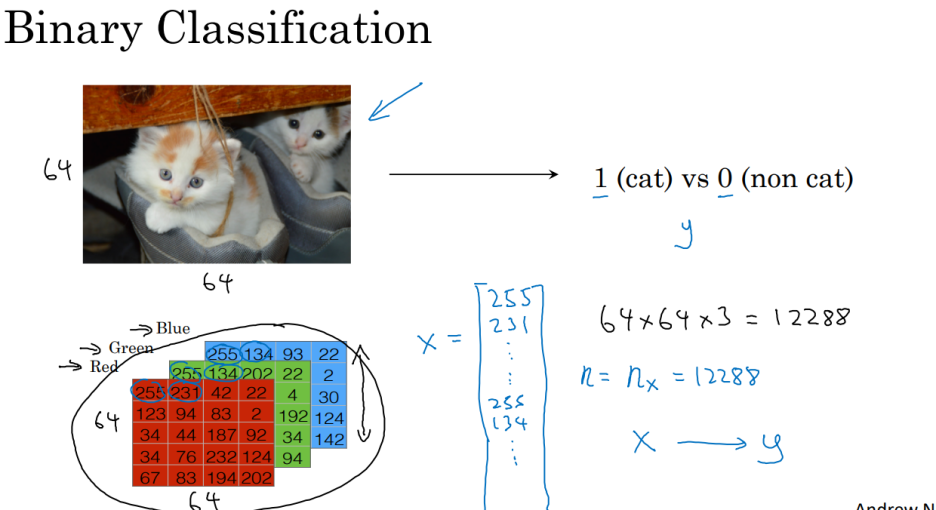
딥러닝을 활용하여,
컴퓨터에게 고양이 사진을 입력하면, 고양이인지 아닌지를 판단하는 프로그램을 만든다고 생각해보겠습니다.
이런 상황처럼, 결과가 2개로 정확하게 나뉘는 것을 "이진 분류 "라고 부릅니다.
이진 분류에 대한 기초지식이 없으신 분들은 강의를 이해할 수 없으실 것 같아서,
이해를 돕기 위해 "이진 분류(Binary Classification)"에 대해 잠깐 알아보겠습니다.

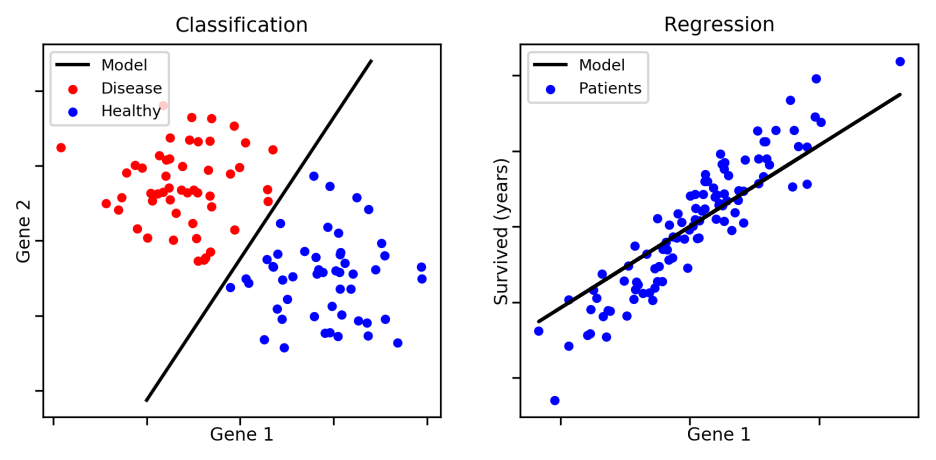
오른쪽은 분류 (Classification) , 왼쪽은 회귀(Regression)를 나타냅니다.
저희는 "이진 분류"에 대해 배워야 하니 오른쪽 자료를 살펴봅시다.
검은 선에 의해서,
검은색 위의 영역은 빨간색 점의 영역, 검은색 아래의 영역은 파란색 점의 영역이 되었는데,
이렇게 데이터들을 하나의 기준으로 두 개로 분류하는 방식을 이진 분류(Binary Classification)라고 하며,
보통은 참(True)과 거짓(False)으로 나누고, 참은 1 거짓은 0으로 표현합니다.
2. 이진 분류 문제를 해결할 때 사용하는 통계기법 : 로지스틱 회귀(Logistic regression)

고양이 사진인지 아닌지를 판단하기 위해서,
아까 본 오른쪽 그림처럼 자료를 두 가지로 적절하게 나누는 선을 하나 그리려 합니다.
여기서 중요한 점은, 고양이 사진을 잘 구분해 내는 적절한 선을 긋는 것인데,
이 적절한 선을 긋는 방법이 로지스틱 회귀(Logistic Regression)입니다.
(헷갈림 주의*) --> "회귀"라는 단어가 들어가서 헷갈리지만 , 분류에 사용하는 통계 기법입니다.
헷갈리니 짧게 정리하면,
1. 이진 분류 문제(고양이 사진인지 아닌지 판별)를 해결하기 위한 적절한 기준선을 그어야 함
2. 그 기준선을 적절하게 긋기 위해서 , 로지스틱 회귀 방법을 사용함
입력하는 이미지의 크기 64*64픽셀이라면,
빨간색, 녹색, 파란색 픽셀의 채도(밝기)에 해당하는 값을 가진 3개의 64x64 행렬이라 볼 수 있을 것입니다.
(위의 자료를 참고하세요) 각각의 픽셀에 적혀있는 숫자는 채도(밝기)를 나타냅니다.
(빨간색, 녹색, 파란색의 밝기가 어떻게 합쳐지냐에 따라 모든 색이 표현됩니다)
일단, 고양이인지 아닌지를 나타내는 0 , 1을 Y라 하고,
픽셀 하나하나에 적혀있는 채도 값들을 합쳐서 하나의 차원 특징 벡터 (feature Vetor) X라 합시다.
참고)) 그림에선 5*4로 생략됐지만, 실제로는 64*64입니다
--> [] 괄호 안은 빨간색 64*64가지 숫자, 파란색 64*64가지 숫자, 초록색 64*64가지 숫자를 나타냅니다.

차원 특징 벡터 X는 위와 같은 열 벡터(행렬)가 되며,
X의 전체 차원(성분) 수 Nx는 64*64*3 = 12888 됩니다.
다음 장으로 넘어가 봅시다.

음... 자료만 보면 갑자기 난이도가 올라가 막막해 보이지만,
강의 내용인 스크립트를 통해 구체적으로 천천히 해석해 봅시다.
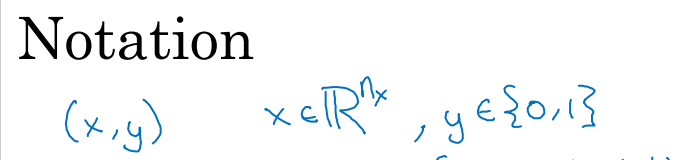
한 쌍의 훈련 값을 (X, Y)라 가정하고,
x는 차원 특징 벡터이고, y는 0과 1달 중 하나의 값만을 가집니다.

훈련 세트(훈련할 사진 데이터들의 집합)를 m이라 해봅시다.
그리고 훈련 세트를 { ( X1 , Y1 ) , (X2 , Y2) ~~~~~ ( Xm-1 , Ym-1) , (Xm , Ym) }라고 합시다.
또, M은 훈련 세트 m을 테스트하기 위한 테스트 세트를 나타내며,
가끔은 강조하기 위해서 M을 M train이라고도 부르겠습니다.

일단 계산을 편리하게 하기 위해서, 벡터 x를 행렬(Metrix)의 모양으로 바꿔보겠습니다.
X1 , X2 ~~~ , Xm(m은 훈련 세트의 수)을 각각을 행렬의 열로 구성하여 , 행렬 X를 만들어봅시다.
그러면, 행렬 X은 m 개의 열이 존재하며, Nx 개의 행이 존재하게 됩니다.

여기서 X1과 Xm의 순서가 반대인 (위의 그림) 방식도 있지만,
딥러닝(Deep Learning)에서는, 이러한 방식보다 왼쪽의 방식을 사용하는 것이 더 쉬워서 왼쪽을 씁니다.

요약하자면, X는 Nx * m 차원 행렬이며, 이것을 파이썬에서 구현하면 X.shape()가 됩니다.
shape()는 행렬의 모양을 가지게 해주는 파이썬 함수입니다.

Y도 같은 메커니즘으로 1 * m 행렬(Metrix)이 됩니다.
새로운 뉴럴 네트워크인 Mtrain을 학습시킬 때는,
또 다른 훈련 예시들에서 Mtrain을 학습시킬 때와 유사한 데이터를 가져오는 것이 좋습니다.
X, Y에 대해 정의해 준 것이고, 바로 이어서 로지스틱 회귀(logistic Regression)에 대해 더 자세히 배워봅시다.
이 내용들은 모두 coursera에서 앤드루 응 교수님의 강의를 요약정리 및 쉽게 재 풀이하여 적은 글이며,
내용에는 생략되거나 변형된 부분이 많으니 직접 강의를 들어보시는 걸 추천드립니다!
이 글은 상업적 목적이 아닌, 한국에서 인공지능을 배우고 싶은 분들을 위해 적은 교육적 목적에서 작성하였습니다
'코세라 앤드류 응 AI 강의 리뷰' 카테고리의 다른 글
| [인공지능 강의 리뷰] 7 - 도함수(Derivative)와 계산 그래프 (Computation Gragh) (0) | 2022.05.09 |
|---|---|
| [인공지능 강의 리뷰] 6 - 경사 하강법(Gradient Descent) (0) | 2022.05.09 |
| [인공지능 강의 리뷰] 5 - 로지스틱 비용 함수(Logistic Regression Cost function) (0) | 2022.05.02 |
| [인공지능 강의 리뷰] 4 - 로지스틱 회귀(Logistic Regression) (0) | 2022.05.02 |
| [인공지능 강의 리뷰] 2 - 지도 학습(Supervised Learning with Neural Network) (0) | 2022.04.19 |
| [인공지능 강의 리뷰] 1 - 신경망(Neural Network) (0) | 2022.04.19 |
| kmooc & coursera - 앤드류 응 교수님의 인공지능 강의 무료 수강 (0) | 2022.04.19 |