Exercise 7 - predict

이전의 구현했던 함수 , optimize()는 학습된 w 및 b를 출력합니다.
학습된 w와 b를 사용하여 데이터 세트 X에 대한 예측치를 예측할 수 있습니다.
predict() 함수를 구현해겠습니다,
predict() 함수를 구현하는데는 아래의 두 가지 단계가 있습니다.
1번째 단계 --> 𝑌̂-hat =𝐴=𝜎(𝑤𝑇𝑋+𝑏) 예측치 계산하기
2번째 단계 --> A(Y-hat)의 값을 0(A<= 0.5인 경우) 또는 1(A > 0.5인 경우)로 변환하고,
예측을 벡터 Y_prediction에 저장합니다. 원하는 경우 for 루프에서 if/else 문을 사용할 수 있습니다.


A는 시그모이드 함수(sigmoid function)의 값이기 때문에 ,
저번에 구현해준 sigmoid() 함수를 불러와 정의해 주면 됩니다.

이제 2번째 단계를 코딩해주면 되는데 , if/else 조건문을 통해서 구현해줍시다!

코드를 작성 후 , 실행하여 정답을 확인해 보겠습니다.
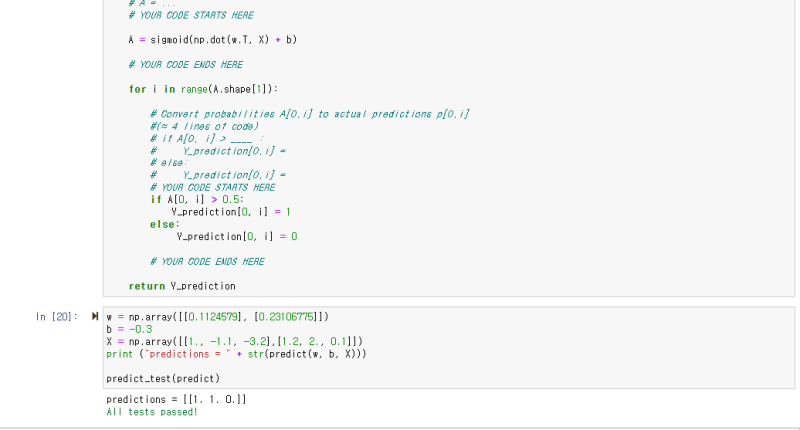
정답을 확인했으니, 다음으로 넘어가 봅시다!
** 주의사항 :
혹시나 jupter notebook에서 실행을 하였는데 , 자꾸 오류가 뜨시는 분은 코드의 위치를 꼭 확인하세요! 파이썬 문법은 코드의 위치를 중심으로 컴파일하기 때문에 , 위치가 중요합니다!

여기서 잠깐! 그동안 저희가 구현한 부분을 정리해보겠습니다.
1 -> 매개변수 w , b를 초기화
2 -> 반복적으로 손실을 최적화하여, 매개변수 w, b를 학습(업데이트)
-> 비용 및 기울기 계산하고 ,
-> 경사 하강법을 사용하여 매개변수 업데이트
3 -> 학습된(업데이트된) w, b를 사용하여 주어진 예제 세트에 대한 레이블 예측
* 레이블이란 , 예측치 y-hat을 이야기합니다!
5 - Merge all funcitons into a model (Exercise 8)

5 - 모든 기능을 모델로 병합하기
이전 부분에서 구현된 기능을 올바른 순서로 함께 모아 전체 모델로 구조화해봅시다.
model() 함수를 구현할 때 , 다음을 코딩하세요
-> 테스트 셋에 대한 예측치 (Y_prediction_test)
-> 훈련 셋에 대한 예측치 (Y_prediction_train)
-> optimize() 함수의 결과 값으로 나온 매개변수, 기울기, 손실의 값
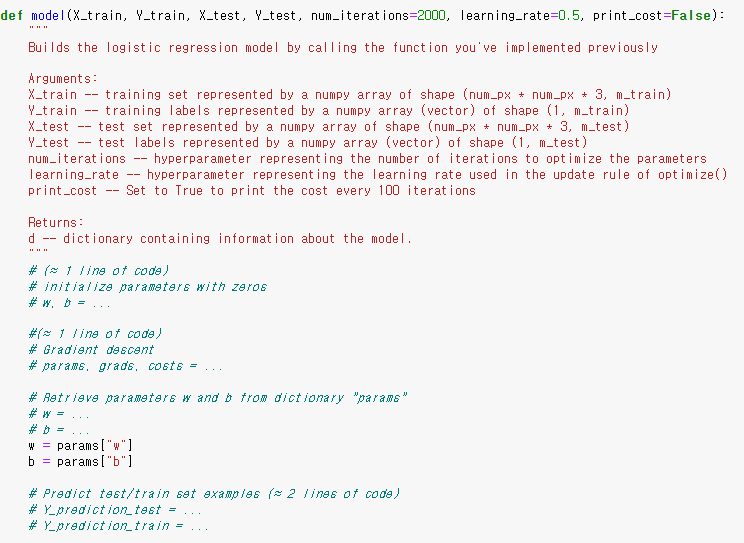

일단 첫 번째로 할 일은 매개변수 w , b를 초기화해야 합니다.
저번에 구현해주었던 initialize_with_zeros(dim)을 불러와줍시다.
( X_train.shape [0]은num_px * num_px * 3입니다.)

--> 아래의 자료를 참고하세요!

그다음으로 코딩해야 할 parms , grads, costs는 optimize() 함수를 불러서 작성합시다.

마지막으로 , Y_predition_test와 Y_predition_train 은
바로 직전 구현해놓은 predict()를 불러와 작성하면 끝입니다!

코드를 작성 후 , 이제 결과를 확인해봅시다.
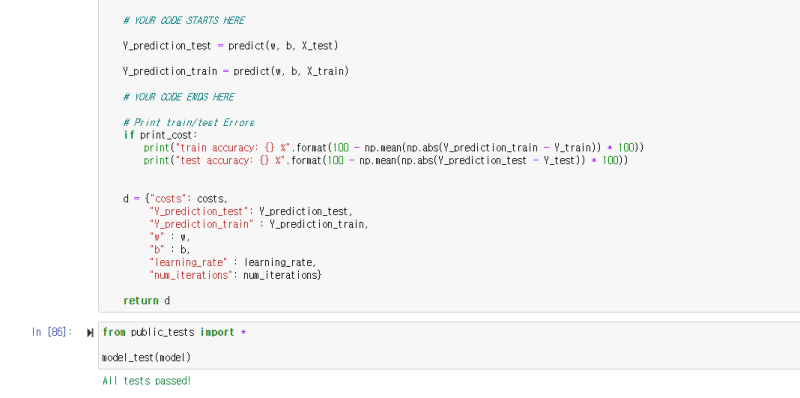
성공입니다! 이제 학습을 해봅시다!

iteration은 반복 횟수이고 , print_cost는 100번 반복당 비용의 변화입니다.
훈련 정확도는 100%에 가깝습니다. --> ( 데이터 셋을 잘 예측한다는 뜻 )
또한 , 테스트 정확도는 70%입니다.
우리가 사용한 작은 데이터 세트와 로지스틱 회귀가 선형 분류기라는 점을 감안할 때,
이 간단한 모델에서는 실제로 나쁘지 않습니다.
하지만 걱정하지 마세요. 다음 주에 더 나은 분류기를 만들 수 있습니다!
또한, 모델이 훈련 데이터에 분명히 과적합(Overfitting)되고 있음을 알 수 있습니다.
--> 과적합(Overfitting)에 대한 내용은 이후에 나옵니다!
이 전문화의 뒷부분에서 정규화를 사용하여 과적합을 줄이는 방법을 배웁니다.
아래 코드를 사용하고 인덱스 변수를 변경하면 테스트 세트의 그림에 대한 예측을 볼 수 있습니다!

이렇게 , 입력한 고양이 사진을 판단해줍니다!
비용 함수와 기울기가 어떻게 변했는지도 확인해봅시다.

학습을 반복함에 따라서 , 점점 비용(오차)의 값이 내려감을 확인할 수 있습니다.

여기서 반복 횟수를 늘려서 더 학습시킬 수도 있지만 ,
그렇게 반복하면 테스트 셋의 정확도는 올라가지만, 오히려 테스트 셋에 대한 정확도는 내려갑니다.
이러한 현상을 과적합(overfitting)이라고 합니다.
6 - Further analysis (optional/ungraded exercise)

6 - 추가 분석
첫 번째 이미지 분류 모델을 구축한 것을 축하합니다!
더 자세히 분석하고 학습률 𝛼에 대한 이야기를 해보겠습니다.
- 학습률 선택 -
경사 하강법이 작동하려면 학습률을 현명하게 선택해야 합니다.
학습률 𝛼은 매개변수를 업데이트하는 속도를 결정합니다.
학습률이 너무 크면 최적의 값을 "오버 샷(overshoot)"할 수 있습니다.
마찬가지로 너무 작으면 최상의 값으로 수렴하기 위해 너무 많은 반복이 필요합니다.
그렇기 때문에 잘 조정된 학습률을 사용하는 것이 중요합니다.
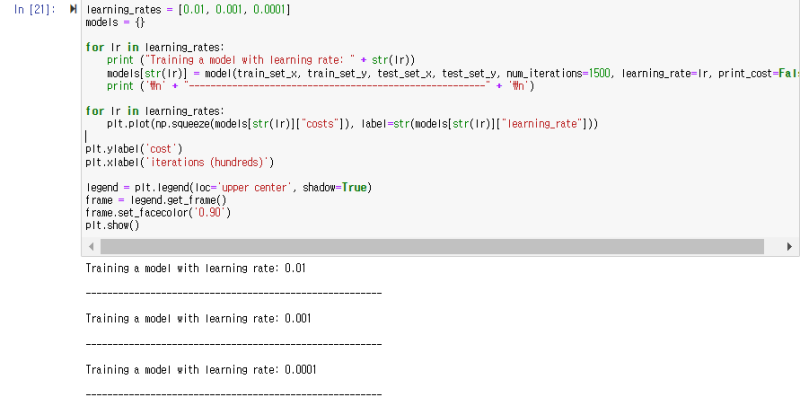
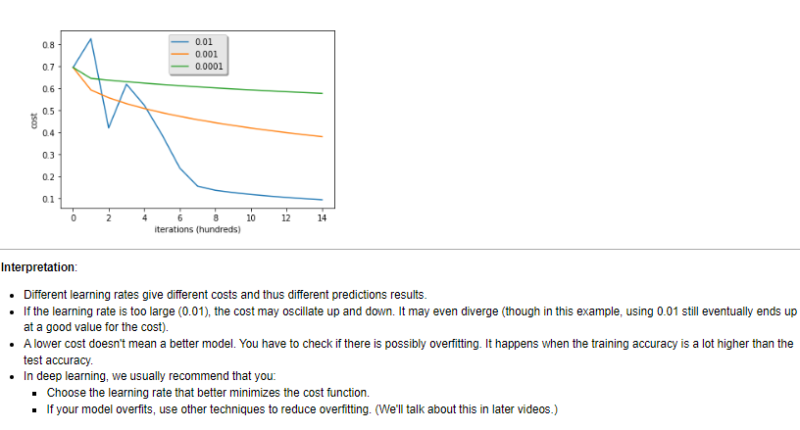
학습률이 다르면 비용(오차)도 다르므로 예측 결과도 다릅니다.
학습률이 너무 크면(0.01) 비용이 위아래로 진동할 수 있습니다.
심지어 발산할 수도 있습니다(이 예에서는 0.01을 사용하면 결국 비용 대비 좋은 가치를 얻게 됩니다).
**더 낮은 비용이 더 나은 모델을 의미하지는 않습니다.
왜냐하면, 과적 합의 가능성이 있기 때문입니다.
--> 과적합은 훈련 정확도가 테스트 정확도보다 훨씬 높을 때 발생합니다.
딥러닝(Deep Learning)에서는 일반적으로 다음을 권장합니다.
-- 비용 함수를 더 잘 최소화하는 학습률을 선택하십시오.
--> 그렇다고 너무 학습률을 낮게 하면 학습 시간이 너무 오래 걸림
-- 모델이 과적합되면 다른 기술을 사용하여 과적합을 줄이십시오. (나중 강의에서 이에 대해 이야기하겠습니다.)
7 - Test with your own image (optional/ungraded exercise)
--> 테스트하고 싶은 사진을 업로드해서 , 만든 모델 시험해보기

제가 가진 에펠탑 사진을 테스트해보았더니 , 고양이가 아니라고 판정 주는 걸 확인할 수 있습니다!

마지막으로 이 과제에서 기억해야 할 사항:
데이터 세트를 전 처리하는 것이 중요합니다.
initialize(), propagate(), optimize() 각 함수를 별도로 구현했습니다. 그런 다음 model()을 구축했습니다.
학습률 조정은 알고리즘에 큰 차이를 만들 수 있습니다.
이상으로 2주 차 강의를 마치도록 하겠습니다! 수고하셨습니다!
이 내용들은 모두 coursera에서 앤드루 응 교수님의 강의를 요약정리 및 쉽게 재 풀이하여 적은 글이며,
내용에는 생략되거나 변형된 부분이 많으니 직접 강의를 들어보시는 걸 추천드립니다!
이 글은 상업적 목적이 아닌, 한국에서 인공지능을 배우고 싶은 분들을 위해 적은 교육적 목적에서 작성하였습니다.
'코세라 앤드류 응 AI 강의 리뷰' 카테고리의 다른 글
| [인공지능 강의 리뷰] 17 - 총정리 퀴즈. 얕은 신경망(Shallow Neural Network) (0) | 2022.05.17 |
|---|---|
| [인공지능 강의 리뷰] 16 - 왜 활성화 함수에 비선형 함수를 써야할까? (0) | 2022.05.17 |
| [인공지능 강의 리뷰] 15 - 뉴럴 네트워크 And 벡터화 표현 (0) | 2022.05.17 |
| [인공지능 강의 리뷰] 13 - 프로그래밍 과제 . 신경망 사고방식을 이용한 로지스틱 회귀 모델 만들기2 (고양이 사진 분류기) (0) | 2022.05.16 |
| [인공지능 강의 리뷰] 12 - 프로그래밍 과제 . 신경망 사고방식을 이용한 로지스틱 회귀 모델 만들기 (고양이 사진 분류기) (0) | 2022.05.16 |
| [인공지능 강의 리뷰] 11 - 신경망 기초 테스트 (Neural Network Basic Quiz) (0) | 2022.05.16 |
| [인공지능 강의 리뷰] 10 - 브로드캐스팅(Broadcating in Python) (0) | 2022.05.16 |